
Introduction
MongoDB is the world’s leading NoSQL database server, and—per DBengine’s ranking, the most widely-known ranking in the database industry—the 5th database server overall in terms of popularity.

MongoDB is a document-oriented database server, using JSON-formatted documents for data rather than the columns and rows of the table structure known to any relational database administrator. This structure allows a flexibility that is difficult to obtain in current relational databases, and is behind the “schema-less” nature of MongoDB. A “collection”, as the MongoDB equivalent of a relational database table is known, does not impose a specific structure on its documents. Practically speaking, this means—among other benefits—that each document in the collection can have differing fields, and a field that exists in one document in the collection need not exist in another. The JSON format also brings embedded arrays, and the ability to index on any attribute among other features.
MongoDB does have great features for developers, but what about the operational management of a production environment? How easy is it to deploy a distributed environment, and then manage it. In this whitepaper, we will cover some of the fundamentals of MongoDB, and show how a clustered environment can be automated with ClusterControl.
Considerations for administering MongoDB
Built-in Redundancy
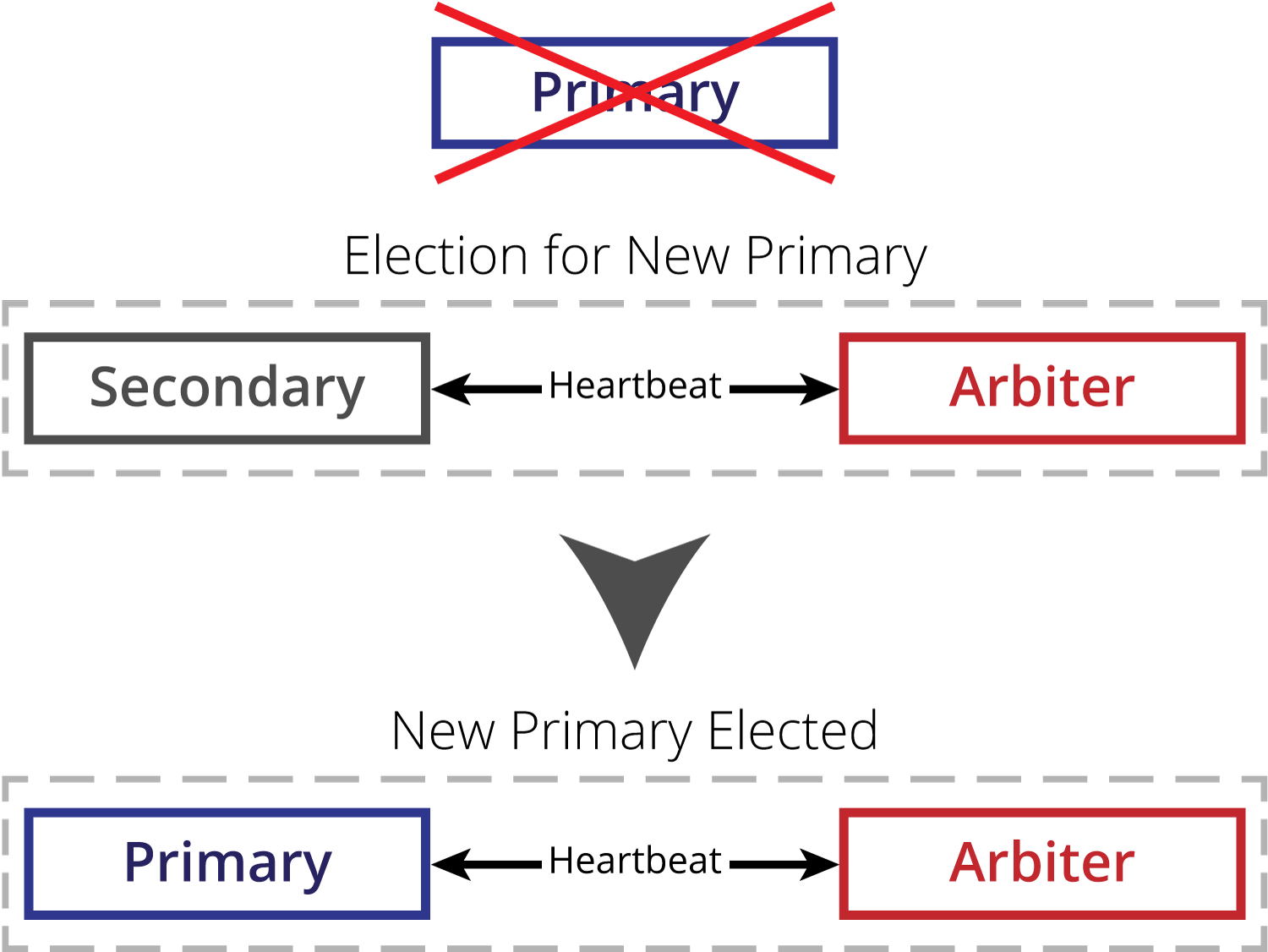
A key feature of MongoDB is its built-in redundancy, in the form of Replication. If you have two or more data nodes, they can be configured as a replica set, in which all data written to the Primary node, is replicated in near real time to the secondary nodes, ensuring multiple copies of the data. In the case of Primary failover, the remaining nodes in the replica set conduct an election and promote the winner to be Primary, a process that typically takes 2-3 seconds, and writes to the replica set can resume. MongoDB also uses a journal for faster, safer writes to the server or replica set, and also employs a “write concern” method through which the level of write redundancy is configured.
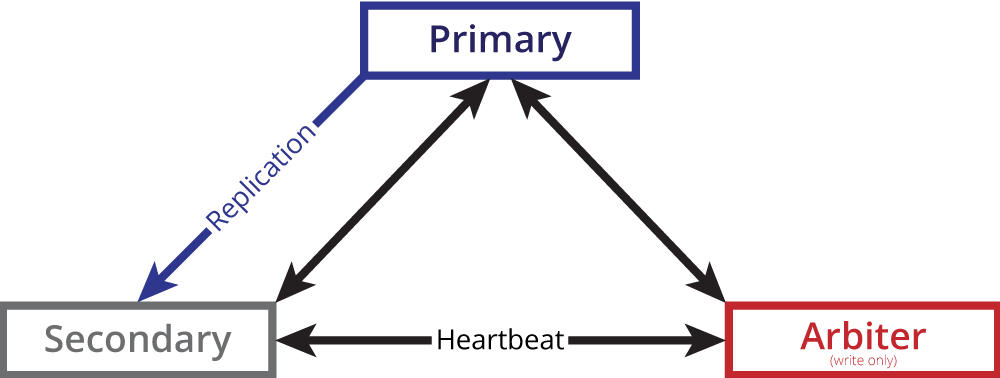
To manually deploy a replica set, the high-level steps are as follows:
- Allocate a single physical or virtual host for each database node, and install the MongoDB command line client on your desktop. For a redundant replica set configuration, a minimum of three nodes are required, at least two of which will be data nodes. One node in the replica set may be configured as an arbiter: this is a mongod process configured only to make up a quorum by providing a vote in the election of a Primary when required. Data is not replicated to arbiter processes.
- Install MongoDB on each node. Some Linux distributions include MongoDB Community Edition, but be aware that these may not include the latest versions. MongoDB Enterprise is available only by download from MongoDB’s website. Similar functionality to MongoDB Enterprise is also available via Percona Server for MongoDB, a drop-in replacement for MongoDB Enterprise or Community Edition.
- Configure the individual mongod.conf configuration files for your replica set, using the “replication parameter”. If you will use a key file for security, configure this now also. Note that using key file security also enables role-based authentication, so you will also need to add users and roles to use the servers. Restart the mongod process on each server.
- Ensure connectivity between nodes. You must ensure that MongoDB replica set nodes can communicate with each other on port 27017, and also that your client(s) can connect to each of the replica set nodes on the same port.
- Using the MongoDB command line client, connect to one of the servers, and run rs.initiate() to initialise your replica set, followed by rs.add() for each additional node. rs.conf() can be used to view the configuration.
While these steps are not as complex as deploying and configuring a MongoDB sharded cluster, or sharding a relational database, they can be onerous and prone to error, especially in larger environments.
Scalability
MongoDB is frequently referred to as “web scale” database software, due to its capacity for scaling horizontally. Like relational databases, it is possible to scale MongoDB vertically, simply by upgrading the physical host on which is resides with more CPU cores, more RAM, faster disks, or even increased bus speed. Vertical scaling has its limits however, both in terms of cost-benefit ratio and diminishing returns, and of technical limitation. To address this, MongoDB has an “auto-sharding” feature, that allows databases to be split across many hosts (or replica sets, for redundancy). While sharding is also possible on relational platforms, unless designed for at database inception, this requires major schema and application redesign, as well as client application redesign, making this a tedious, time-consuming, and error-prone process.
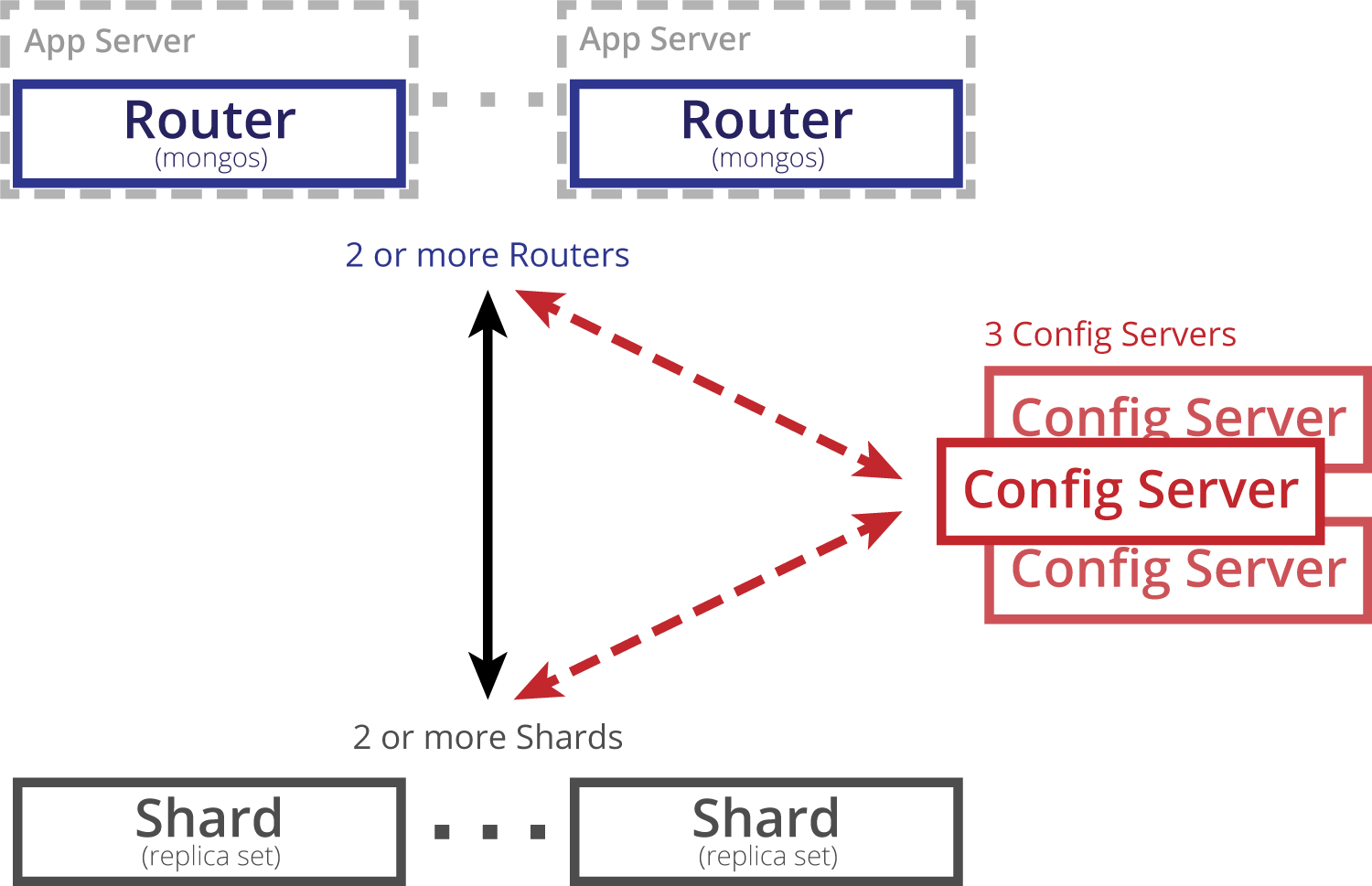
MongoDB sharding works by introducing a router process, through which clients connect to the sharded cluster, and configuration servers, which store the cluster meta-data, the location in the cluster of each document. When a client submits a query to the router process, it first refers to the config servers to obtain the locations of the documents, and then obtains the query results directly from the individual servers or replica sets (shards). Sharding is carried out on a per collection basis.
A critically important parameter here, for performance purposes, is the “shard key”, an indexed field or compound field that exists in each document in a collection. It is this that defines the write distribution across shards of a collection. As such, a poorly-chosen shard key can have a very detrimental effect on performance. For example, a purely time-series based shard key may result in all writes going to a single node for extended periods of time. However, a hashed shard key, while evenly distributing writes across shards, may impact read performance as a result set is retrieved from many nodes.
Arbiters
A MongoDB arbiter is a mongod process that has been configured not to act as a data node, but to provide only the function of voting when a replica set Primary is to be elected, to break ties and guard against a split vote. An arbiter may not become Primary, as it does not hold a copy of the data or accept writes. While it is possible to have more than one arbiter in a replica set, it is generally not recommended.
Delayed Replica Set Members
Delayed replica set members add an additional level of redundancy, maintaining a state that is a fixed number of seconds behind the Primary. As delayed members are a “rolling backup” or a running “historical” snapshot of the data set, they can help to recover from various types of human error.
Delayed members are “hidden” replica set members, invisible to client applications, and so cannot be queried directly. They also may not become Primary during normal operations, and must be reconfigured manually in the case that they are to be used to recover from error.

Backups
Backing up a replica set or sharded cluster is carried out via the “mongodump“ command line utility. When used with the --oplog parameter, this creates a dump of the database that includes an oplog, to create a point-in-time snapshot of the state of a mongod instance. Using mongorestore with the --replayOplog parameter, you can then fully restore the data state at the time the backup completed, avoiding inconsistency.
For more advanced backup requirements, a third party tool called “mongodb-consistent-backup” - also command line based - is available that provides fully consistent backups of sharded clusters, a complex procedure, given that sharded databases are distributed across multiple hosts.
Monitoring
There are a number of commercial tools, both official and unofficial, available on the market for monitoring MongoDB. These tools, in general, are single product management utilities, focusing on MongoDB exclusively. Many focus only on certain specific aspects, such as collection management in an existing MongoDB architecture, or on backups, or on deployment. Without proper planning, this can lead to a situation where a proliferation of additional tools must be deployed and managed in your environment.
The command line tools provided with MongoDB, “mongotop” and “mongostat” can provided a detailed view of your environments performance, and can be used to diagnose issues. In addition, MongoDB’s “mongo” command line client can also run “rs.status()” - or in a sharded cluster “sh.status() - to view the status of replica sets or clusters and their member hosts. The “db.stats()” command returns a document that addresses storage use and data volumes, and their are equivalents for collections, as well as other calls to access many internal metrics.
Synopsis
This has been a brief synopsis of considerations for administering MongoDB. Even at such a high level though, it should immediately be obvious that while it is possible to administer a replica set or sharded cluster from the command line using available tools, this does not scale in an environment with many replica sets or with a large production sharded cluster. In medium to large environments comprising many hosts and databases, it quickly becomes unfeasible to manage everything with command line tools and scripts. While internal tools and scripts can be developed to deploy and maintain the environment, this adds the burden of managing new development, revision control systems, and processes. A simple upgrade of a database server may become a complex process if tooling changes are required to support new database server versions.
But without internal tools and scripts, how do we automate and manage MongoDB clusters?
Automation with ClusterControl
ClusterControl from Severalnines is designed to answer these questions and more. ClusterControl allows you to deploy, backup, and monitor not only your MongoDB replica sets and sharded clusters, but also your other Open Source database assets. MySQL with native replication, NDB or Galera, and PostgreSQL, as well as MongoDB are managed in a single web-based unified interface. Here we take a look at ClusterControl’s features in more detail.
Deployment
A core feature of ClusterControl is the deployment of MongoDB replica sets and sharded clusters, in addition to its other supported database servers and clusters. If your environment has already been deployed, ClusterControl has that covered: you can simply import the existing environment and begin managing it right away.
Once you have logged in, simply select the operation, Deploy or Import, and follow the wizard-like interface.
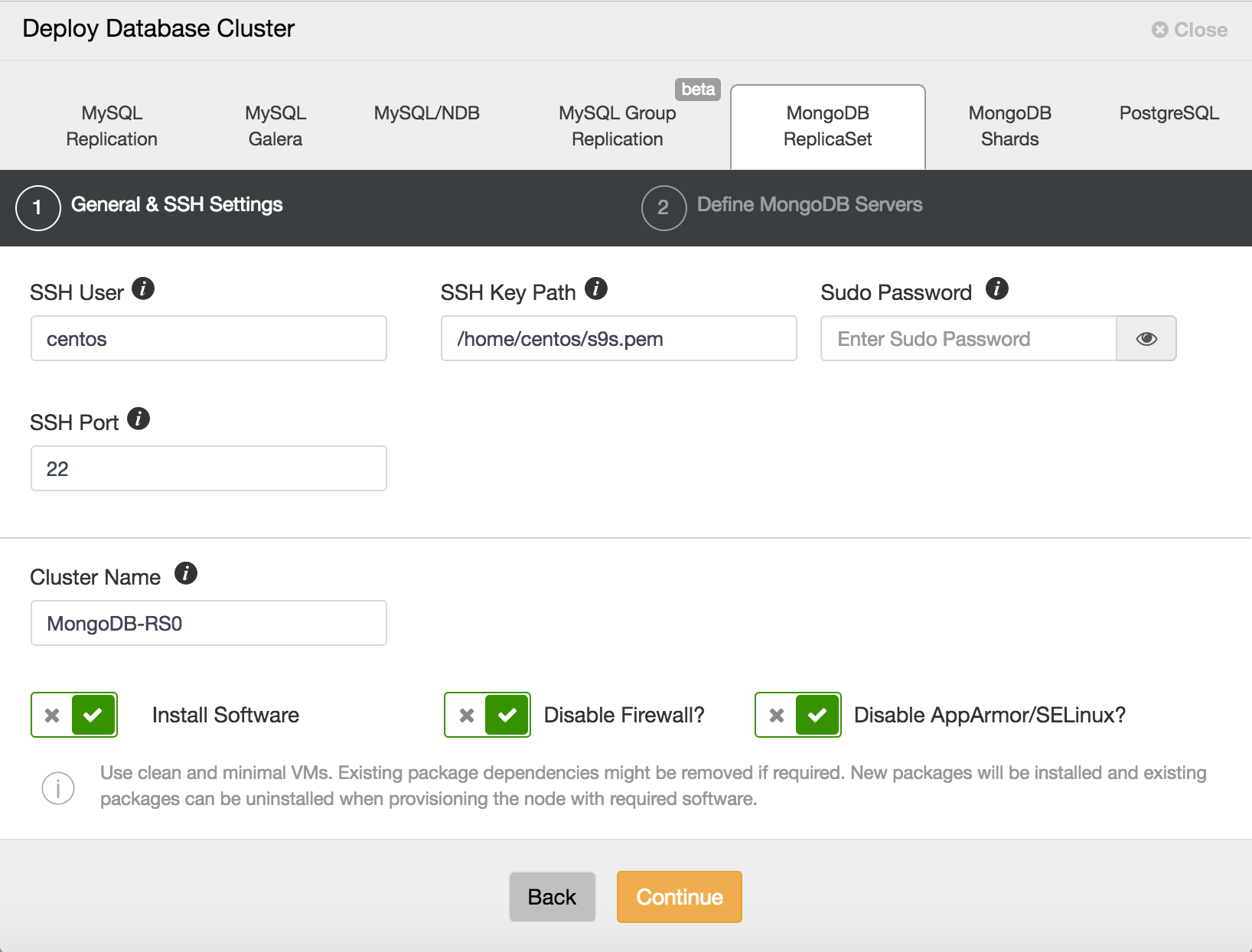
On the initial deployment screen you will provide ssh credentials appropriate to the hosts on which you are deploying your replica set or cluster. As ClusterControl uses password-less ssh to connect to and configure your hosts, an ssh key is required. For security reasons, it is advisable to use an unprivileged user account to log into the hosts, so a sudo password can be provided to facilitate administrative tasks. If the user account does not prompt for a sudo password, this is not needed.
You also have the option to disable the iptables or ufw firewall, and to disable AppArmor or SELinux, on the host to avoid issue with initial deployment.
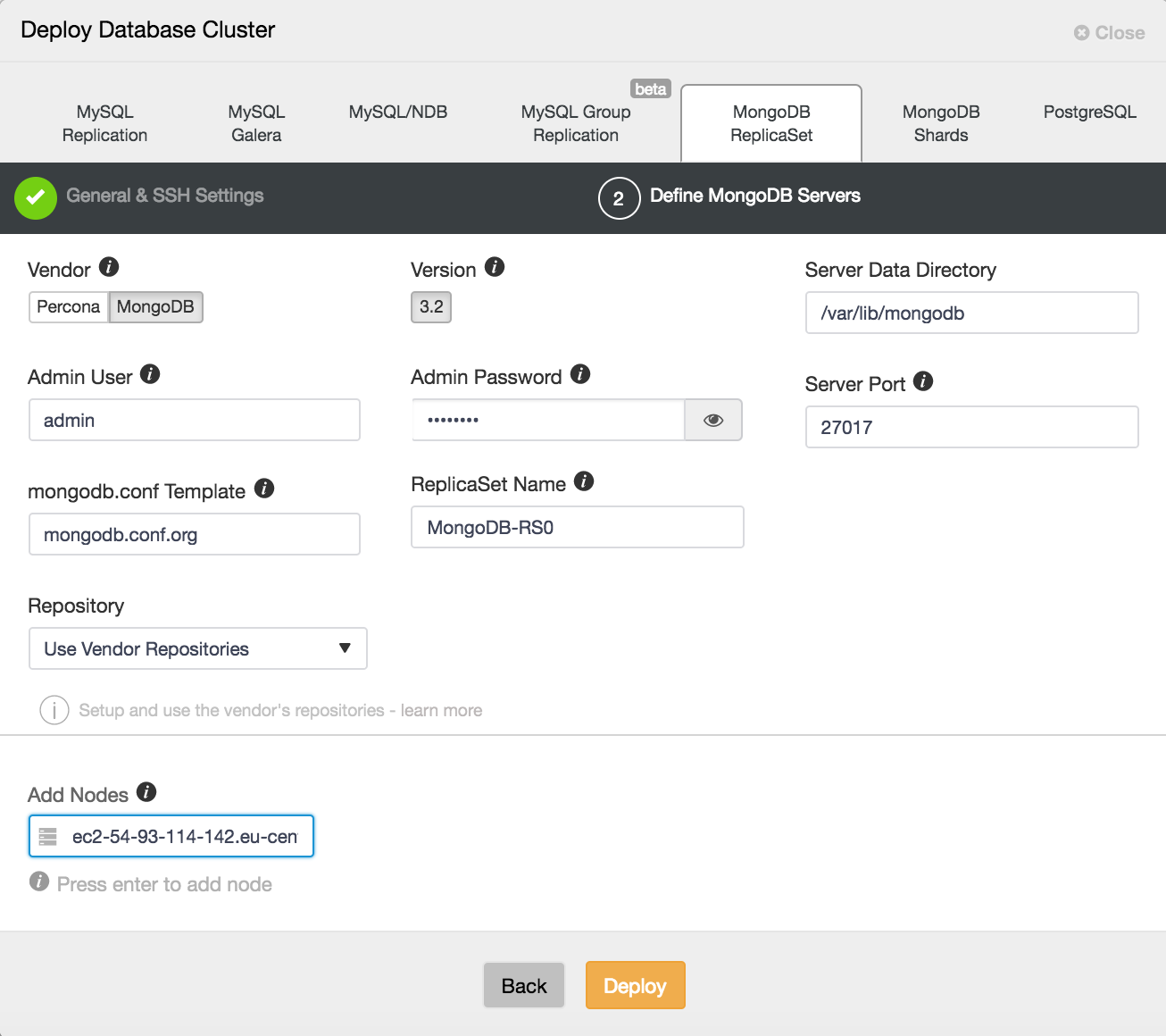
On the following screen, you can choose to install MongoDB binaries from either MongoDB Inc or from Percona. Here also, you must specify your MongoDB administrative user account and password as user level security is mandated. On this screen also, you can see which configuration template is being used. ClusterControl uses configuration file templates to ensure repeatable deployments. Templates are stored on the ClusterControl host and can be edited directly there, or through the ClusterControl UI.
As shown in Figure 8, you can also choose to use the vendor repositories, if you wish, or choose your own repository. In addition, you can create a new repository on the ClusterControl host automatically, to freeze the version of MongoDB that ClusterControl will deploy to the current release. Once you carried out the appropriate configuration here, click Deploy, to deploy your replica set.
As mentioned previously, ClusterControl can deploy not only Replica Sets, but also Sharded Clusters. Two methods of doing so are supported. First, you can convert an existing MongoDB Replica Set into a Sharded Cluster, as shown in Figure 10, below.
When “Convert to Shard” is clicked, you are prompted to add at least one Config server (for production environments, you should add three), and a router, also known as a “mongos” process.
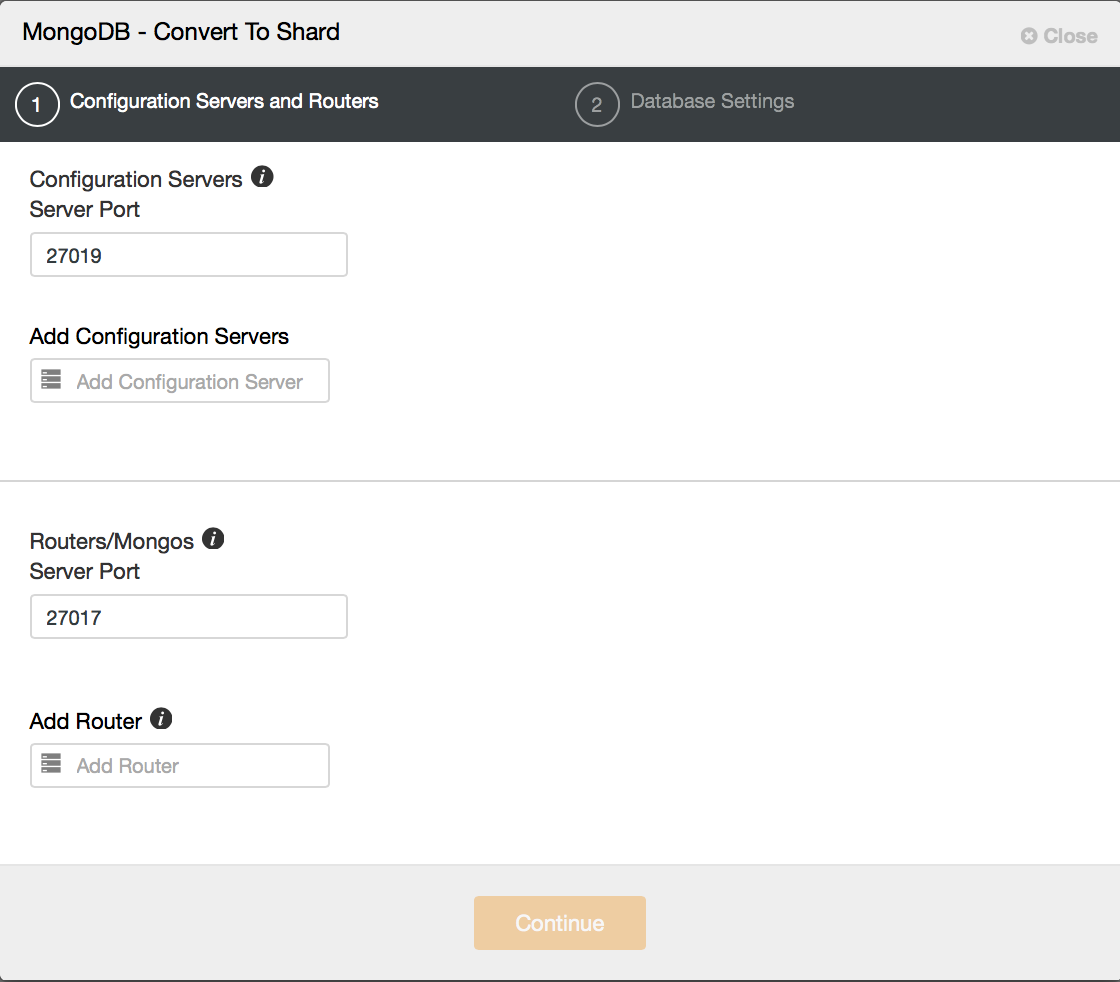
The final stage is to choose your MongoDB configuration templates for config server and router, as well as your data directory. Finally, click deploy.
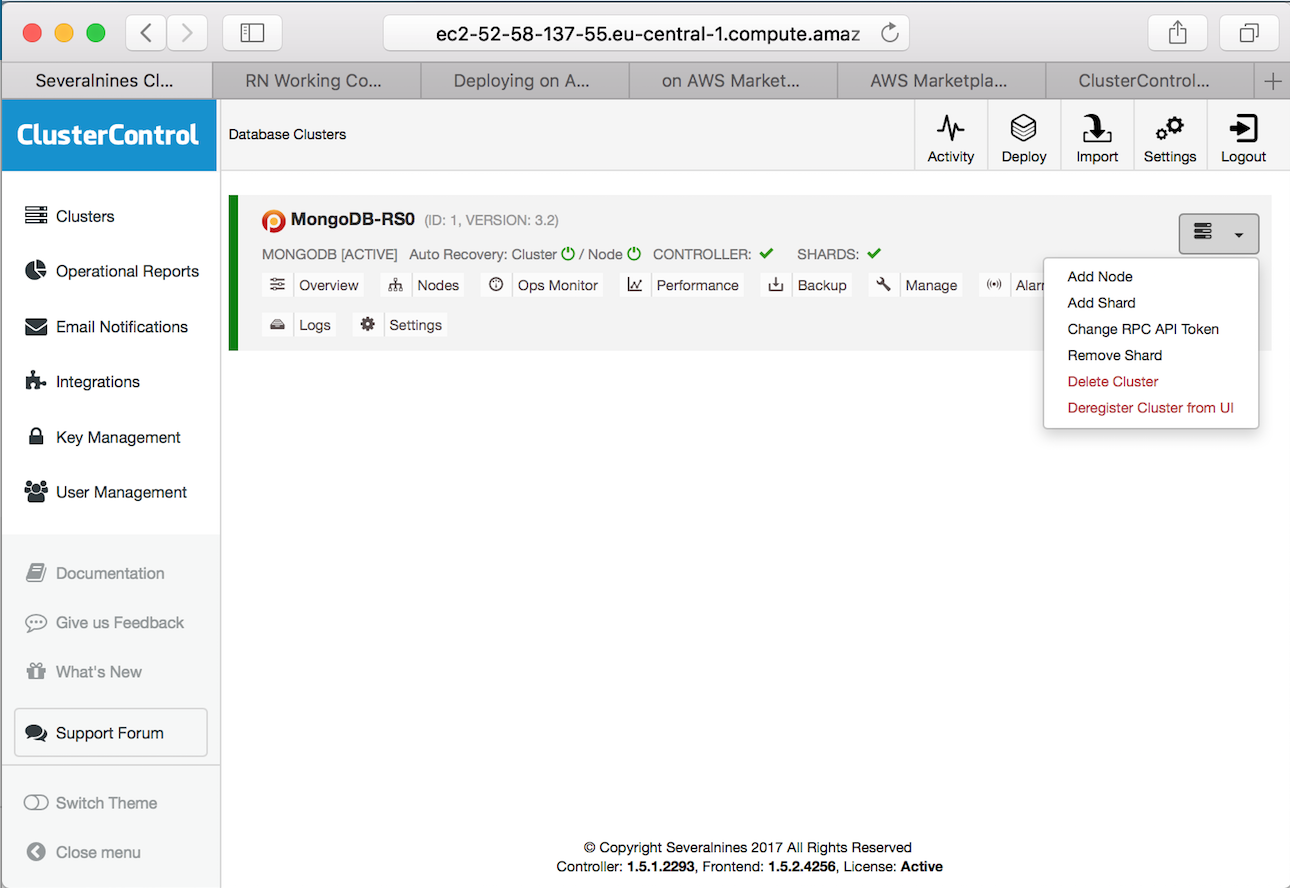
When complete, as you can see in Figure 12, below, your Database Clusters screen will show your shard health instead of individual instances. It is also possible to add additional shards as needed from this view, as shown.
Backup & Restore
Backups being critical to any production environment, ClusterControl has support for fully consistent backup and restore of your MongoDB replica set or sharded cluster.
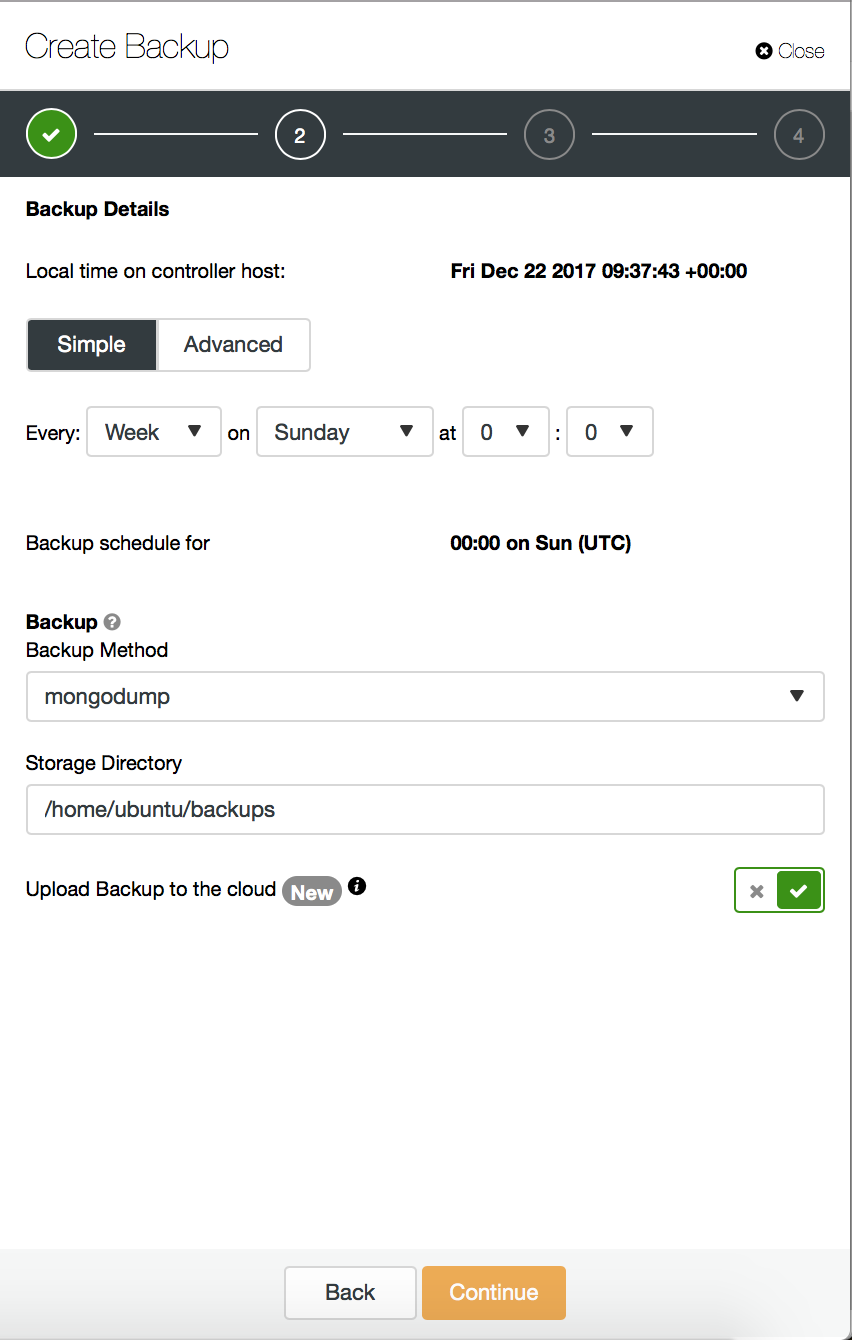
Backups can be taken manually, or can be scheduled regularly or once off. Centralisation of backups is supported, with backups stored either on the Controller filesystem, including network-mounted directories, or uploaded to a preconfigured Cloud provider - currently supported providers are Google Cloud Platform and Amazon Web Services. This allows you to take full advantage of advanced lifecycle management functionality provided by Amazon and Google for such features as custom retention schedules, long-term archival, and encryption at rest, among others. Backup retention is configurable; you can choose to retain your backup for any time period, or to never delete backups. AES256 encryption is employed to secure your backups against rogue elements.
For rapid recovery, backups can be restored directly into the backed up cluster - ClusterControl handles the full restore process from launch to cluster recovery, removing error prone manual steps from the process.
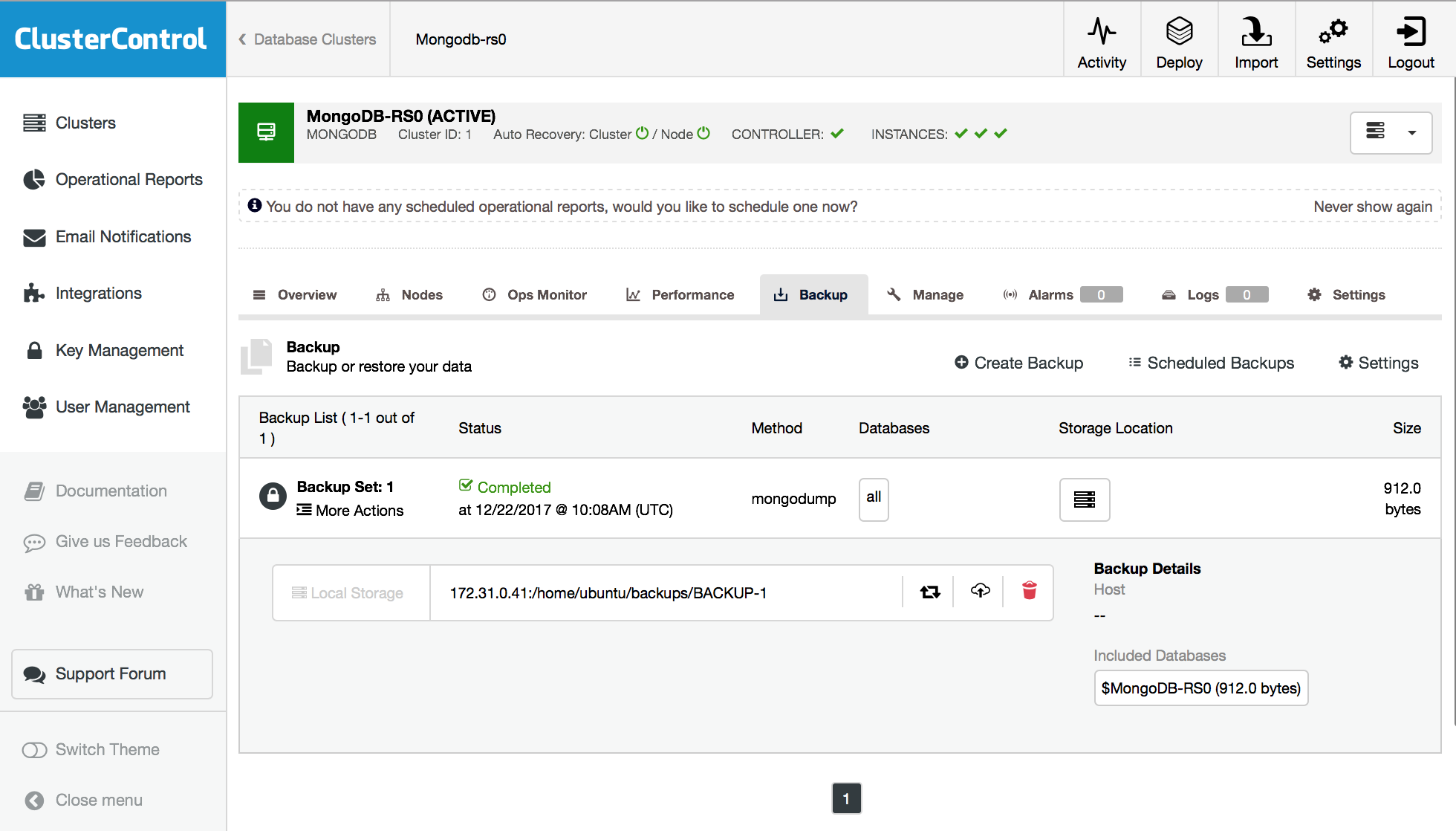
Existing backups can also be administered directly from the ClusterControl UI, as shown in Figure 14, below.
Monitoring
ClusterControl’s enterprise monitoring functionality includes configurable custom dashboards capable of displaying any or all of the standard host metrics, as well as all key MongoDB performance metrics.
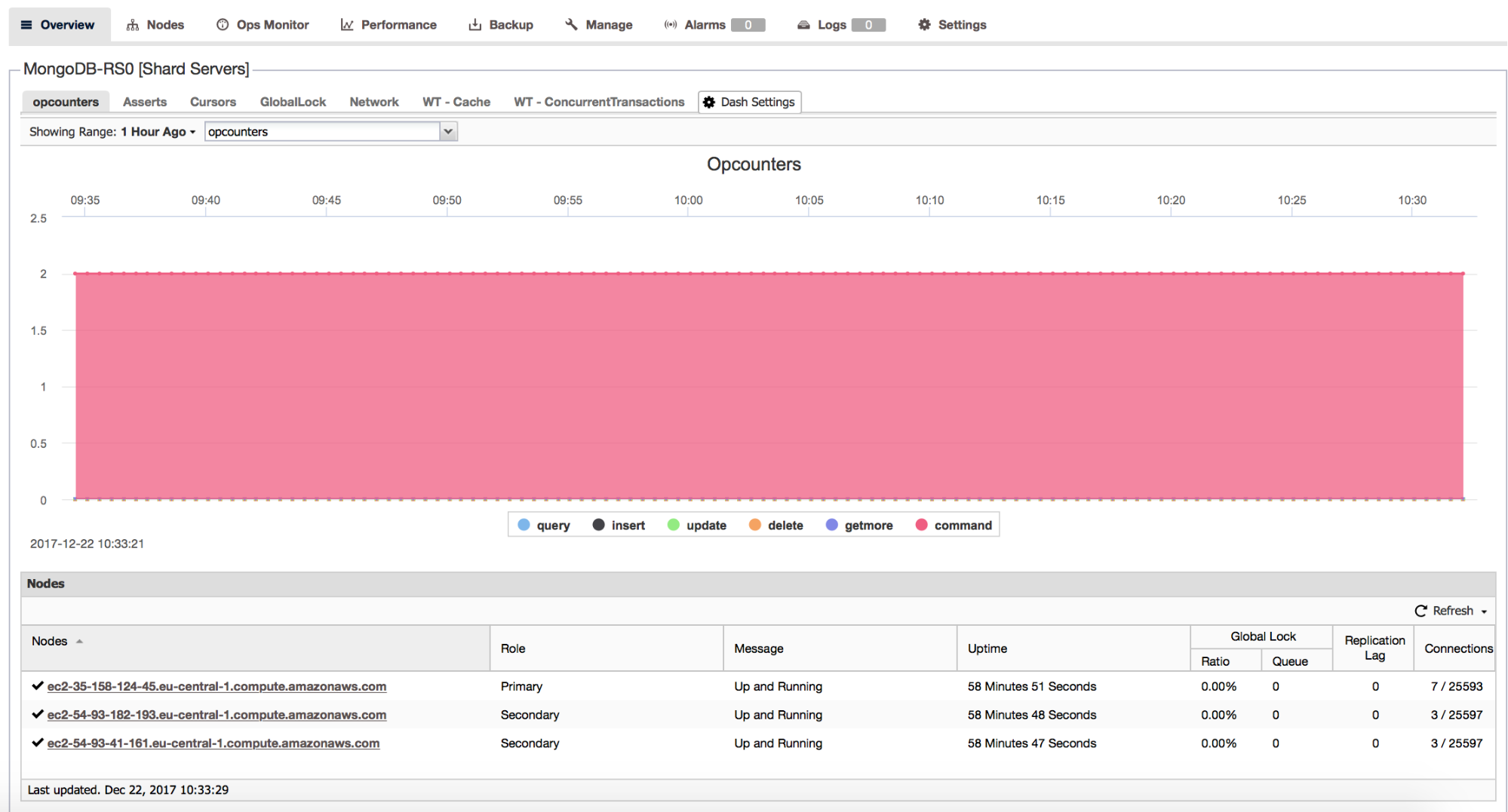
The default Overview includes a view of all MongoDB OpCounters, as well as tabs for Asserts, Cursors, GlobalLock, Network, WT-Cache, and WT-ConcurrentTransactions, givign a comprehensive view of your cluster’s performance. This dashboard is fully editable, allowing the addition of any key metric from a list of dozens, as well as the facility to combine metrics for a complete holistic view of your deployment.
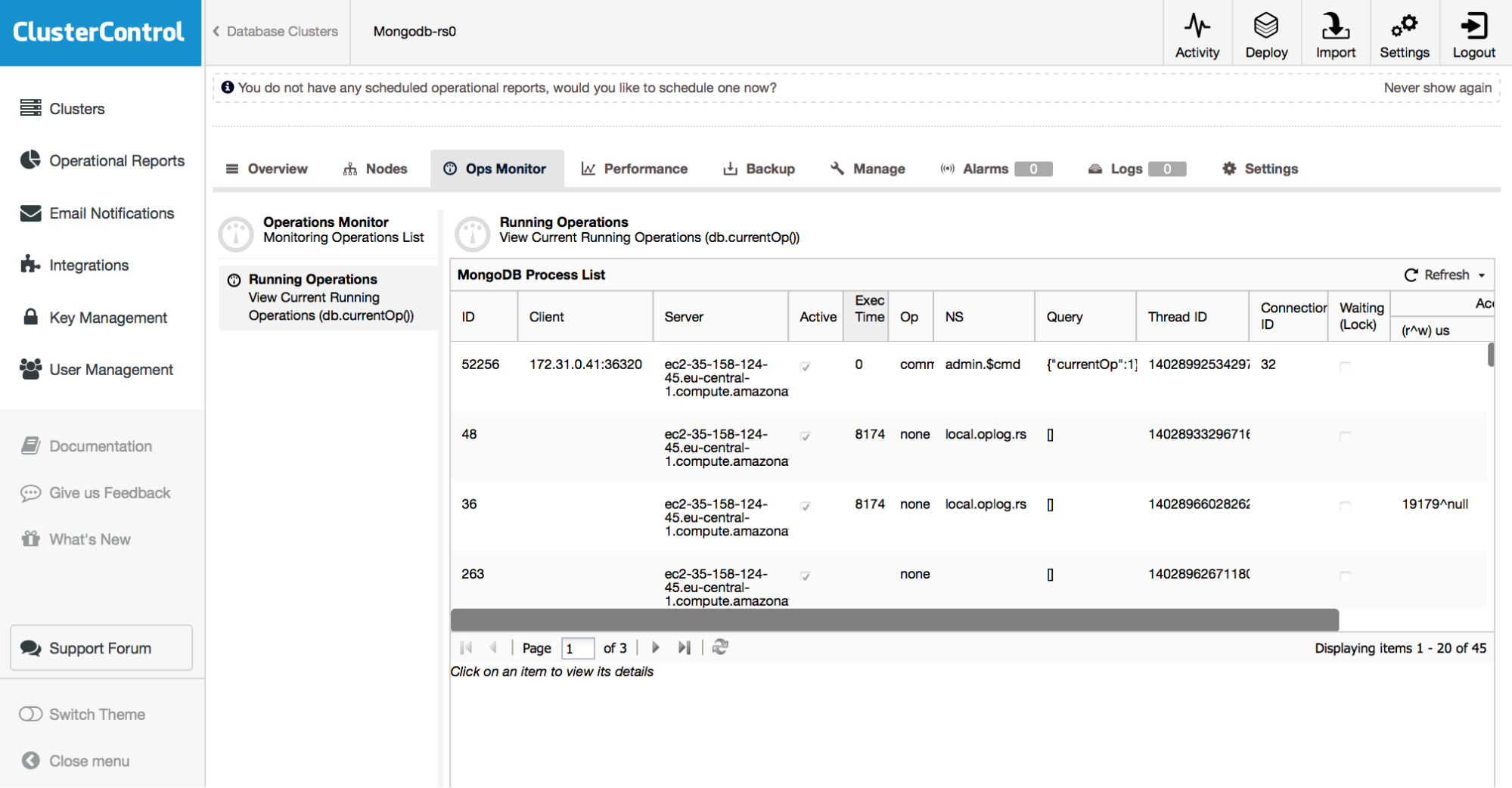
In addition, the Ops Monitor (Figure 16) gives a view of all running operations, helping track down any performance issues in your cluster.
MongoDB Advisors
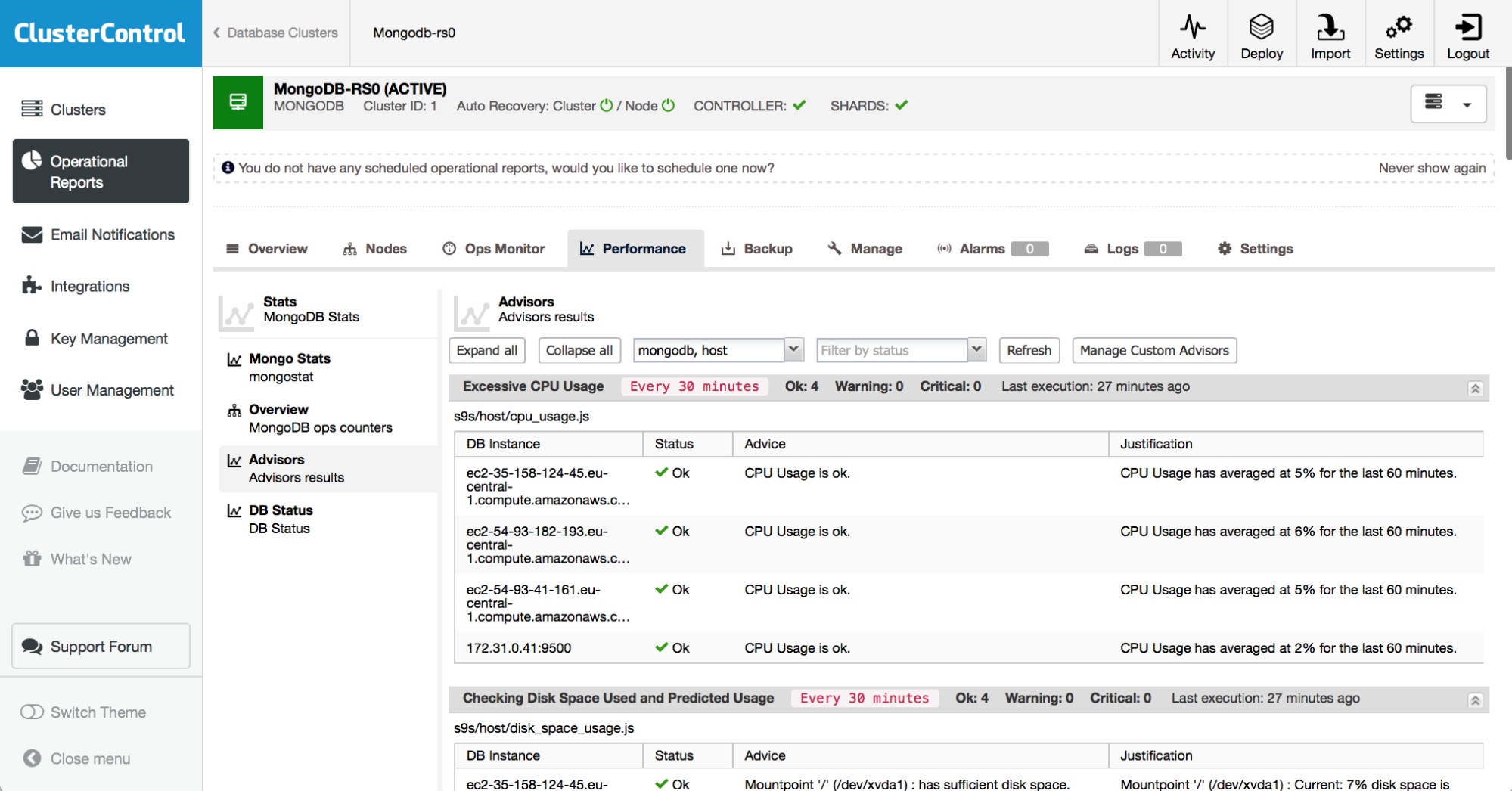
Advanced monitoring functionality is included through ClusterControl “Advisors”, found under the “Performance” tab, as shown in Figure 17. Advisors provide specific advice on how to address issues in areas such as performance, security, log management, configuration, storage space, and others.
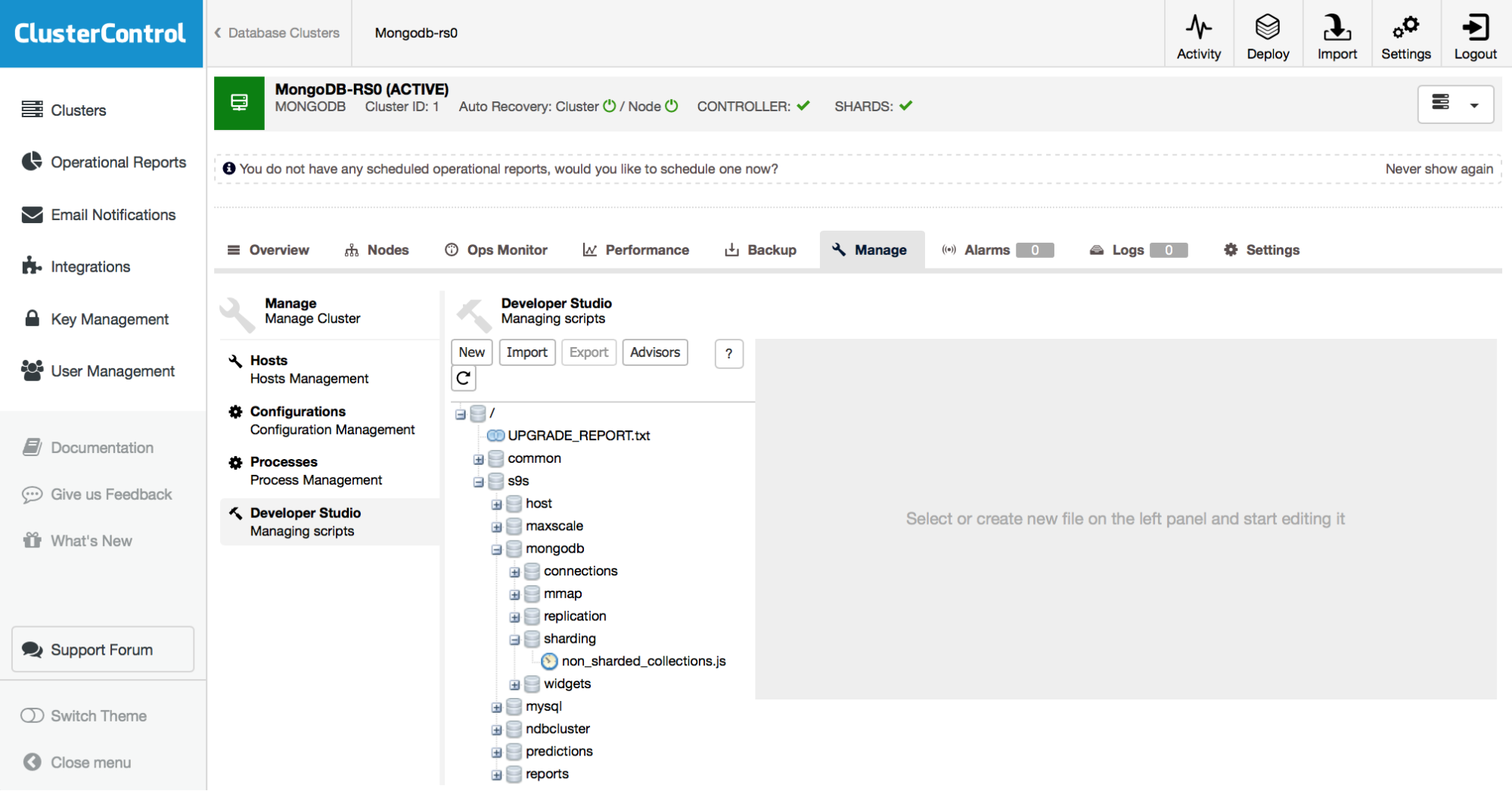
Advisors are fully customisable through the built in Developer Studio (Figure 18), using the ClusterControl Domain-Specific Language (DSL), a Javascript-like language. With the ClusterControl DSL, new Advisors can be created, or existing Advisors can be extended for an experience fully tailored for your environment.
While, as mentioned, you can create your own custom advisors, several are provided for key performance and management criteria out of the box. These include Replication Lag and Replication Window, critically important metrics for cluster resiliency, as well as Error Detection, an Authentication/Authorisation Sanity Check to aid in security management and the Unsharded Databases and Collections Check for sharded clusters, to ensure that everything that should be sharded, is sharded.
There are also more general purpose advisors such as the Disk Mount Options advisor, to ensure maximum performance of your cluster.
Integrations
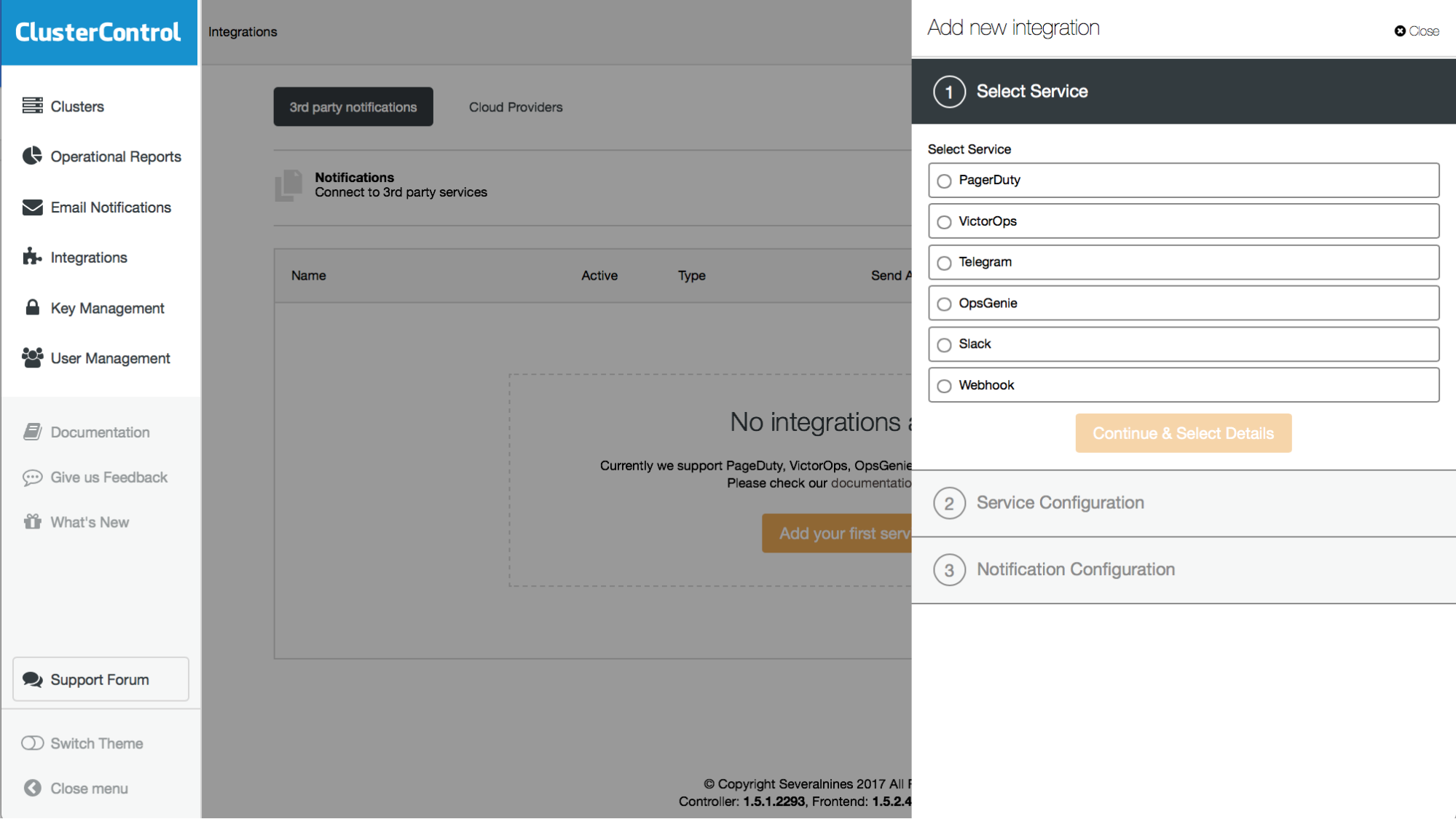
For ease of integration into your existing corporate environment, ClusterControl supports integrations with commonly used products and technologies. Currently supported integrations are PagerDuty, VictorOps, OpsGenie, Slack, and Telegram. Integration of other applications is supported through Webhooks.
Command-Line Access
For ease of automation, ClusterControl also includes a commandline utility, ‘s9s’, which can also be installed from the website. This can be used to deploy, monitor, and backup ClusterControl resources, such as nodes, and clusters. In addition, s9s also allows you to manage users, and to view the status of running processes on ClusterControl-managed nodes.
Below are a few examples to get you started, and the documentation can be found on the website and also through context sensitive help in the tool itself.
Help
$ s9s --helpUsage
s9s COMMAND [OPTION...]Where COMMAND is:
account - to manage accounts on clusters;
backup - to view, create and restore database backups;
cluster - to list and manipulate clusters;
job - to view jobs;
maint - to view and manipulate maintenance periods;
metatype - to print metatype information;
node - to handle nodes;
process - to view processes running on nodes;
script - to manage and execute scripts;
server - to manage hardware resources;
user - to manage users.
MongoDB deploy cluster example
The following command deploys a three-node MongoDB ReplicaSet by MongoDB Inc, with "replica_set_0":
$ s9s cluster --create --cluster-type=mongodb --nodes="10.0.0.148;10.0.0.189;10.0.0.219"--vendor=10gen --provider-version='3.2'--os-user=root --db-admin='admin'--db-admin-passwd='MyS3cr3tPass'--cluster-name='MongoDB ReplicaSet 3.2'--waitMongoDB create backup example
The following command creates a backup using mongodump on 10.0.0.148 and stored it inside ClusterControl host under /storage/backups directory:
$ s9s backup --create --backup-method=mongodump --cluster-name='MongoDB ReplicaSet 3.2'--nodes=10.0.0.148 --backup-directory=/storage/backupsMongoDB cluster status example
The following command shows the status of the created MongoDB ReplicaSet:
$ s9s cluster --stat
MongoDB ReplicaSet 3.2 Name: MongoDB ReplicaSet 3.2 Owner: dba/users
ID: 6 State: STARTED
Type: MONGODB Vendor: 10gen 3.2
Status: All nodes are operational.
Alarms: 0 crit 0 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 0 finsd 0 runng
Config: '/etc/cmon.d/cmon_6.cnf'
LogFile: '/var/log/cmon_6.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.148 1 6% 992M 139M 0B 0B 19G 15G 7.3K/s33K/s
10.0.0.189 1 6% 992M 144M 0B 0B 19G 15G 8.8K/s54K/s
10.0.0.219 1 5% 992M 143M 0B 0B 19G 15G 8.0K/s51K/s
10.0.0.156 2 10% 3.6G 1.4G 0B 0B 19G 4.5G 301K/s75K/sMongoDB node status example
The following command returns configuration options for MongoDB node, 10.0.0.148:
$ s9s node --list-config --nodes=10.0.0.148
GROUP OPTION NAME VALUE
storage dbPath /var/lib/mongodb
storage journal.enabled true
storage engine wiredTiger
mmapv1 smallFiles false
systemLog destination file
systemLog path /var/log/mongodb/mongod.log
systemLog logAppend true
net port 27017
processManagement fork true
processManagement pidFilePath /var/run/mongodb/mongod.pid
setParameter enableLocalhostAuthBypass true
replication replSetName replica_set_0
sharding clusterRole shardsvr
sharding security.keyFile /etc/mongo-cluster.key
Total: 14This is just a brief outline of s9s functionality, and many more operations are possible, as you can see above. The s9s command line tool facilitates scripting of many ClusterControl operations, allowing integration with your new and existing management utilities and scripts.
In Conclusion
In this Whitepaper, we have reviewed the challenges involved in managing MongoDB at scale and have introduced mitigating features of ClusterControl from Severalnines. As a best of breed database management solution, ClusterControl brings consistency and reliability to your database environment, and simplifies your database operations at scale.