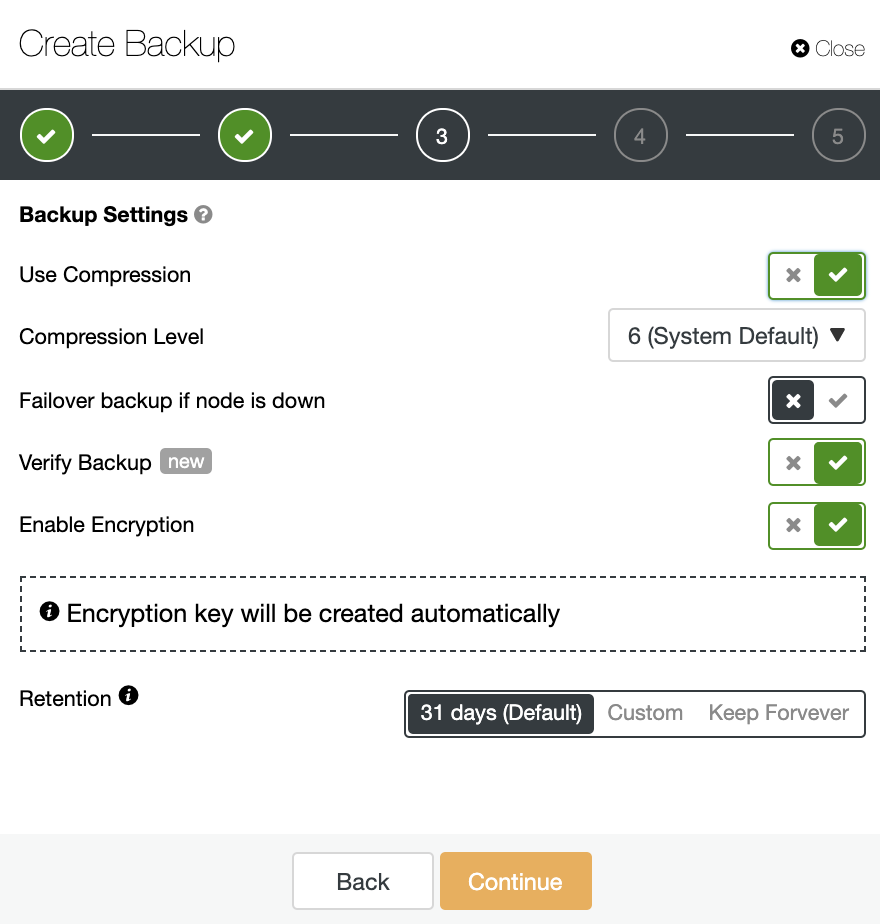
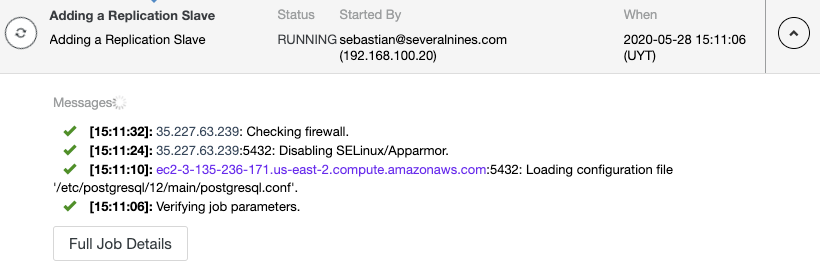
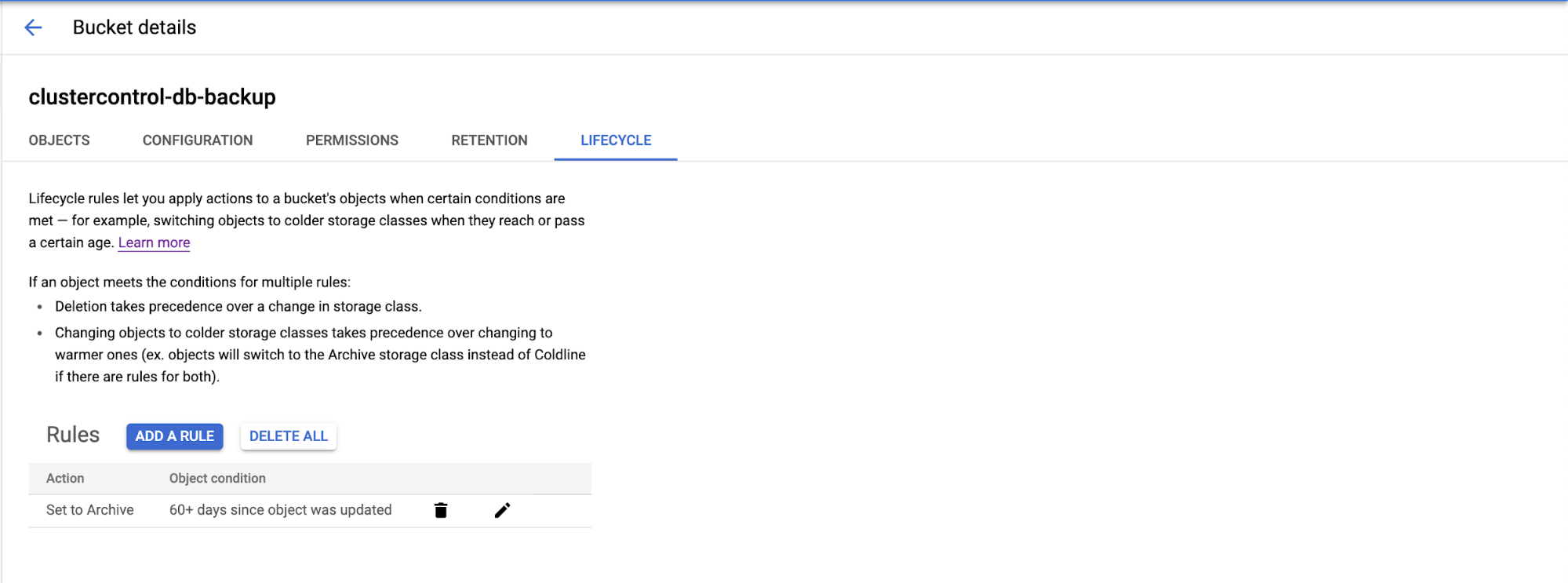
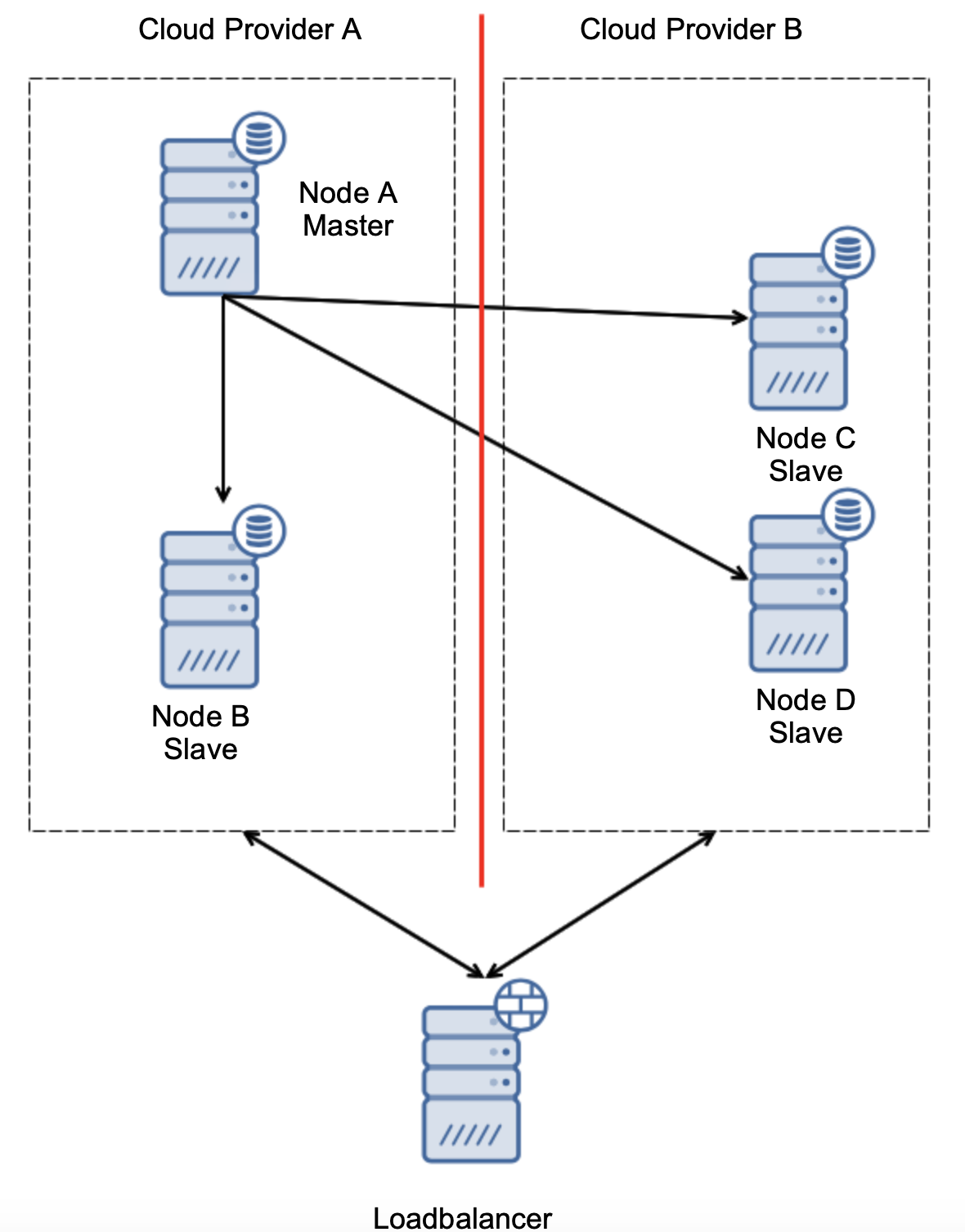
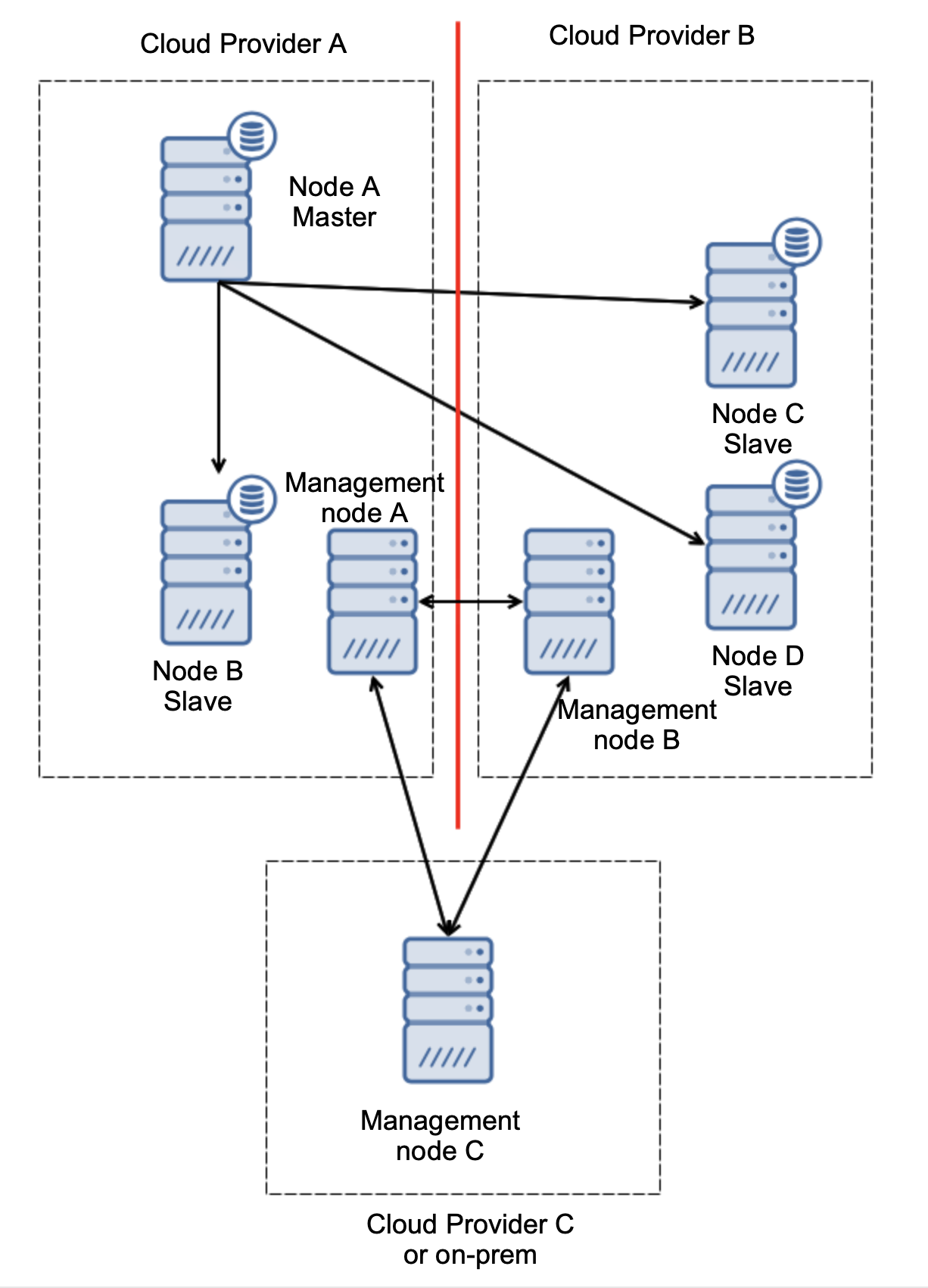
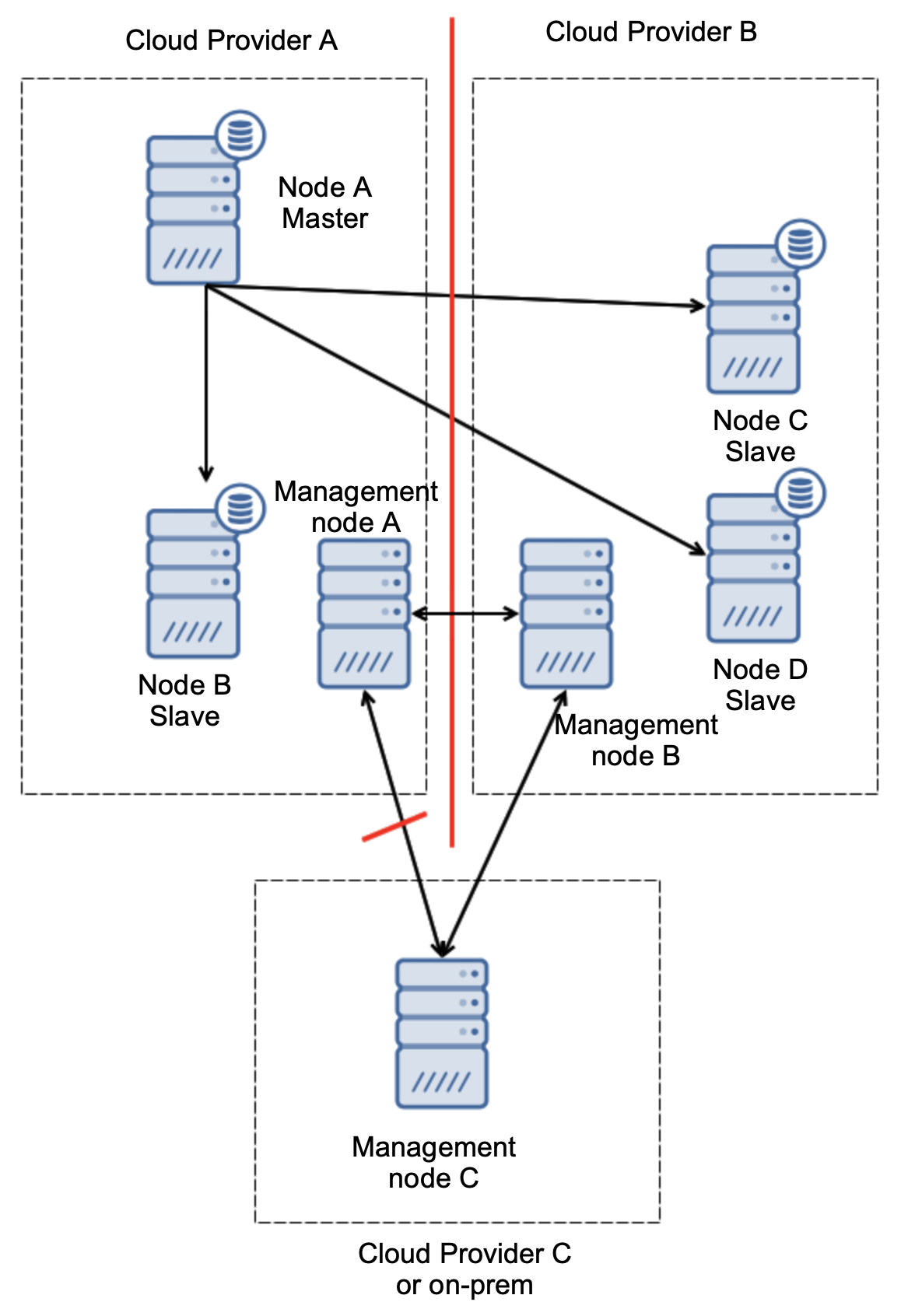
When your database workload is over stressed, you first want to look at what queries are running in an attempt to see the pattern of the query. Is it write heavy? Read heavy? Where is the bottleneck?
Identifying Query Issues
To figure it out you can enable the general log or the slow log to try to capture the queries which are running and writing to the file. You also can read from the binary log (as binary log captures all the changes in the database) and look at reads directly from the running processlist in the database. You can even capture the query from the network perspective by looking through tcpdump.
What to do next? You can analyze the query that is written to general log file, slow log file, binary log to check if there is something interesting going on (eg. bottleneck in the query).
Percona has a tool to analyze these type queries, named pt-query-digest. It is included when you install the Percona Toolkit, a collection of utilities tools that help DBA to manage their databases. In this blog we will take a look at this tool and how it compares to the Query Management features of ClusterControl.
Installation Procedure
Percona repositories support two packages Linux Distribution for setup, which is Debian-based and RPM-based package distribution. The installation are just simple as shown below :
Debian-based package (Ubuntu, Debian)
Configure Percona package repositories by download the package
wget https://repo.percona.com/apt/percona-release_latest.generic_all.debAnd then install the downloaded package using dpkg
sudo dpkg -i percona-release_latest.generic_all.debAfter that, just run the installation from package manager
sudo apt-get install percona-toolkitRPM-based package (RHEL, CentOS, Oracle Enterprise Linux, Amazon AMI)
Configure Percona package repositories by installing the rpm package directly.
sudo yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm After that, just run the installation from package manager
sudo apt-get install percona-toolkitPercona utilities will be installed in your machine, and you just need to use it.
Query Workload Analyze
There are several ways to generate the statistics from the query workload using pt-query-digest, below is the command how to do it using a slow query file, general file, show processlist in database, and read through binary log.
Generate from show processlist database
pt-query-digest --processlist h=localhost,D=sbt,u=sbtest,p=12qwaszx --output slowlog > /tmp/slow_query.logGenerate from the slow query files / general query file
pt-query-digest mysql-slow.log > /tmp/slow_query.logGenerate from binary log. Before you run the pt-query-digest, you need to extract the binary log into readable format using mysqlbinlog. Don’t forget to add --type option and type binlog as the source.
pt-query-digest --type binlog mysql-bin.000001.txt > slow_query.logAfter finish generating the file, you will see the report as shown below :
# 12s user time, 170ms system time, 27.44M rss, 221.79M vsz
# Current date: Sun May 10 21:40:47 2020
# Hostname: n2
# Files: mysql-1
# Overall: 94.92k total, 47 unique, 2.79k QPS, 27.90x concurrency ________
# Time range: 2020-05-10 21:39:37 to 21:40:11
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 949s 6us 1s 10ms 42ms 42ms 2ms
# Lock time 31s 0 1s 327us 80us 11ms 22us
# Rows sent 69.36k 0 490 0.75 0.99 11.30 0
# Rows examine 196.34k 0 490 2.12 0.99 21.03 0.99
# Rows affecte 55.28k 0 15 0.60 0.99 1.26 0
# Bytes sent 13.12M 11 6.08k 144.93 299.03 219.02 51.63
# Query size 15.11M 5 922 166.86 258.32 83.13 174.84
# Profile
# Rank Query ID Response time Calls R/Call V/M Ite
# ==== ============================= ============== ===== ====== ===== ===
# 1 0xCE367F5CFFCAF46E816F682E... 162.6485 17.1% 199 0.8173 0.03 SELECT order_line? stock?
# 2 0x360F872745C81781F8F75EDE... 107.4898 11.3% 14837 0.0072 0.02 SELECT stock?
# 3 0xE0CE1933D0392DA3A42FAA7C... 102.2281 10.8% 14866 0.0069 0.03 SELECT item?
# 4 0x492B86BCB2B1AE1278147F95... 98.7658 10.4% 14854 0.0066 0.04 INSERT order_line?
# 5 0x9D086C2B787DC3A308043A0F... 93.8240 9.9% 14865 0.0063 0.02 UPDATE stock?
# 6 0x5812BF2C6ED2B9DAACA5D21B... 53.9681 5.7% 1289 0.0419 0.05 UPDATE customer?
# 7 0x51C0DD7AF0A6D908579C28C0... 44.3869 4.7% 864 0.0514 0.03 SELECT customer?
# 8 0xFFFCA4D67EA0A788813031B8... 41.2123 4.3% 3250 0.0127 0.01 COMMIT
# 9 0xFDDEE3813C59881488D9C47F... 36.0707 3.8% 1180 0.0306 0.02 UPDATE customer?
# 10 0x8FBBE0AFA061755CCC1C27AB... 31.6417 3.3% 1305 0.0242 0.03 UPDATE orders?
# 11 0x8AA6EB56551923DB9A49E40A... 23.3281 2.5% 1522 0.0153 0.04 SELECT customer? warehouse?
# 12 0xF34C10B3DA8DB048A630D4C7... 21.1662 2.2% 1305 0.0162 0.03 UPDATE order_line?
# 13 0x59DBA67188951C532AFC2598... 20.8006 2.2% 1503 0.0138 0.33 INSERT new_orders?
# 14 0xDADBEB0FBFA537F5D8722F42... 17.2802 1.8% 1290 0.0134 0.03 SELECT customer?
# 15 0x597A805ADA793440507F3334... 16.4394 1.7% 1516 0.0108 0.03 INSERT orders?
# 16 0x1B1EA568857A6AAC6544B44A... 13.9560 1.5% 1309 0.0107 0.05 SELECT new_orders?
# 17 0xCE3EDD98779478DE17154DCE... 12.1470 1.3% 1322 0.0092 0.05 INSERT history?
# 18 0x9DFD75E88091AA333A777668... 11.6842 1.2% 1311 0.0089 0.05 SELECT orders?
# MISC 0xMISC 39.6393 4.2% 16334 0.0024 0.0 <29 ITEMS>
# Query 1: 6.03 QPS, 4.93x concurrency, ID 0xCE367F5CFFCAF46E816F682E53C0CF03 at byte 30449473
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.03
# Time range: 2020-05-10 21:39:37 to 21:40:10
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 199
# Exec time 17 163s 302ms 1s 817ms 992ms 164ms 816ms
# Lock time 0 9ms 30us 114us 44us 84us 18us 36us
# Rows sent 0 199 1 1 1 1 0 1
# Rows examine 39 76.91k 306 468 395.75 441.81 27.41 381.65
# Rows affecte 0 0 0 0 0 0 0 0
# Bytes sent 0 15.54k 79 80 79.96 76.28 0 76.28
# Query size 0 74.30k 382 384 382.35 381.65 0 381.65
# String:
# Databases sbt
# Hosts localhost
# Last errno 0
# Users sbtest
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms ################################################################
# 1s ####
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sbt` LIKE 'order_line6'\G
# SHOW CREATE TABLE `sbt`.`order_line6`\G
# SHOW TABLE STATUS FROM `sbt` LIKE 'stock6'\G
# SHOW CREATE TABLE `sbt`.`stock6`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT COUNT(DISTINCT (s_i_id))
FROM order_line6, stock6
WHERE ol_w_id = 1
AND ol_d_id = 1
AND ol_o_id < 3050
AND ol_o_id >= 3030
AND s_w_id= 1
AND s_i_id=ol_i_id
AND s_quantity < 18\G
# Query 2: 436.38 QPS, 3.16x concurrency, ID 0x360F872745C81781F8F75EDE9DD44246 at byte 30021546
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.02
# Time range: 2020-05-10 21:39:37 to 21:40:11
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 15 14837
# Exec time 11 107s 44us 233ms 7ms 33ms 13ms 3ms
# Lock time 1 522ms 15us 496us 35us 84us 28us 23us
# Rows sent 20 14.49k 1 1 1 1 0 1
# Rows examine 7 14.49k 1 1 1 1 0 1
# Rows affecte 0 0 0 0 0 0 0 0
# Bytes sent 28 3.74M 252 282 264.46 271.23 8.65 258.32
# Query size 19 3.01M 209 215 213.05 212.52 2.85 212.52
# String:
# Databases sbt
# Hosts localhost
# Last errno 0
# Users sbtest
# Query_time distribution
# 1us
# 10us #
# 100us ##
# 1ms ################################################################
# 10ms #############
# 100ms #
# 1s
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sbt` LIKE 'stock9'\G
# SHOW CREATE TABLE `sbt`.`stock9`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT s_quantity, s_data, s_dist_01 s_dist
FROM stock9
WHERE s_i_id = 60407 AND s_w_id= 2 FOR UPDATE\GAs you can see on the above pt-query-digest report result, we can divided into 3 parts.
Summary Report
There is much information you can find in the summary report, starting from the hostname server, the date you execute the command, information related to the query were logged, QPS, and time frame capture. Beside that, you also can see statistics of timing on each Attribute.
# 12s user time, 170ms system time, 27.44M rss, 221.79M vsz
# Current date: Sun May 10 21:40:47 2020
# Hostname: n2
# Files: mysql-1
# Overall: 94.92k total, 47 unique, 2.79k QPS, 27.90x concurrency ________
# Time range: 2020-05-10 21:39:37 to 21:40:11
# Attribute total min max avg 95% stddev median
# ============ ======= ======= ======= ======= ======= ======= =======
# Exec time 949s 6us 1s 10ms 42ms 42ms 2ms
# Lock time 31s 0 1s 327us 80us 11ms 22us
# Rows sent 69.36k 0 490 0.75 0.99 11.30 0
# Rows examine 196.34k 0 490 2.12 0.99 21.03 0.99
# Rows affecte 55.28k 0 15 0.60 0.99 1.26 0
# Bytes sent 13.12M 11 6.08k 144.93 299.03 219.02 51.63
# Query size 15.11M 5 922 166.86 258.32 83.13 174.84Query Profiling Based on Rank
You can see useful information in the profiling query.
# Profile
# Rank Query ID Response time Calls R/Call V/M Ite
# ==== ============================= ============== ===== ====== ===== ===
# 1 0xCE367F5CFFCAF46E816F682E... 162.6485 17.1% 199 0.8173 0.03 SELECT order_line? stock?
# 2 0x360F872745C81781F8F75EDE... 107.4898 11.3% 14837 0.0072 0.02 SELECT stock?There is a lot of information such as the queries running, response time of the query (including the percentage calculation), how many calls the query is making, and reads per call.
Query Distribution
Query distribution statistics describe detailed information based on query profiling rank, you can see the QPS concurrency, statistics information related to the query Attribute.
# Query 1: 6.03 QPS, 4.93x concurrency, ID 0xCE367F5CFFCAF46E816F682E53C0CF03 at byte 30449473
# This item is included in the report because it matches --limit.
# Scores: V/M = 0.03
# Time range: 2020-05-10 21:39:37 to 21:40:10
# Attribute pct total min max avg 95% stddev median
# ============ === ======= ======= ======= ======= ======= ======= =======
# Count 0 199
# Exec time 17 163s 302ms 1s 817ms 992ms 164ms 816ms
# Lock time 0 9ms 30us 114us 44us 84us 18us 36us
# Rows sent 0 199 1 1 1 1 0 1
# Rows examine 39 76.91k 306 468 395.75 441.81 27.41 381.65
# Rows affecte 0 0 0 0 0 0 0 0
# Bytes sent 0 15.54k 79 80 79.96 76.28 0 76.28
# Query size 0 74.30k 382 384 382.35 381.65 0 381.65
# String:
# Databases sbt
# Hosts localhost
# Last errno 0
# Users sbtest
# Query_time distribution
# 1us
# 10us
# 100us
# 1ms
# 10ms
# 100ms ################################################################
# 1s ####
# 10s+
# Tables
# SHOW TABLE STATUS FROM `sbt` LIKE 'order_line6'\G
# SHOW CREATE TABLE `sbt`.`order_line6`\G
# SHOW TABLE STATUS FROM `sbt` LIKE 'stock6'\G
# SHOW CREATE TABLE `sbt`.`stock6`\G
# EXPLAIN /*!50100 PARTITIONS*/
SELECT COUNT(DISTINCT (s_i_id))
FROM order_line6, stock6
WHERE ol_w_id = 1
AND ol_d_id = 1
AND ol_o_id < 3050
AND ol_o_id >= 3030
AND s_w_id= 1
AND s_i_id=ol_i_id
AND s_quantity < 18\GThere is also information regarding query time distribution, host, user, and database.
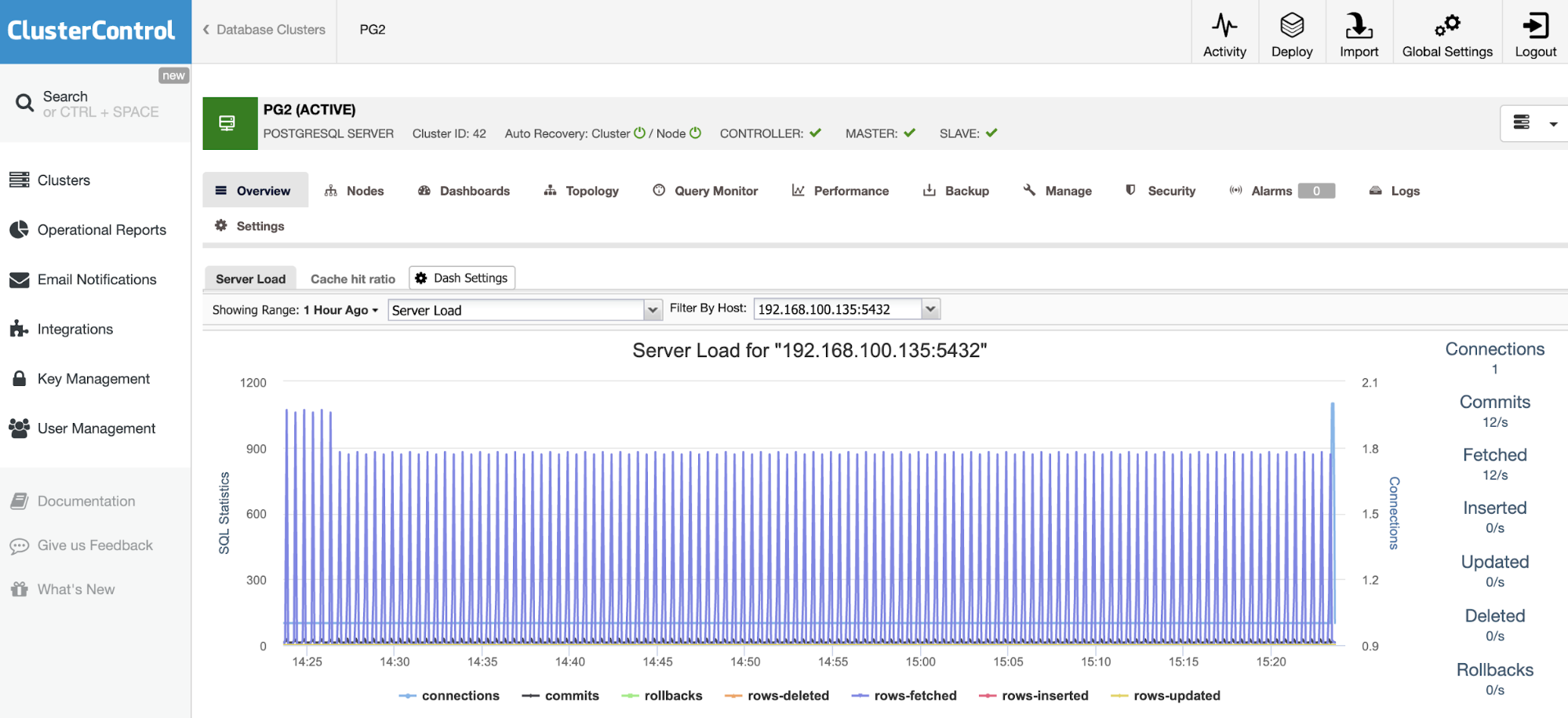
Query Monitoring with ClusterControl
ClusterControl has a Query Monitoring feature you can find in the Query Monitor tab as shown below.

You can see information related to the query that is executed in the database, including statistical information and execution time. You can also configure the Query Monitor Setting which is still on the same page. There is an option to enable the slow query and queries not using index by clicking on Settings

You just need to set the Long Query Time, which is the threshold of the query that categorizes for long based on execution time. Also there is an option to enable the query that is not using indexes.
Conclusion
Monitoring and analyzing the query workload can be beneficial so you know and understand your database workload, both pt-query-digest and the ClusterControl Query Monitor provide information related to the query running in the database to help you achieve that understanding.